

Sampling is one of the most essential steps in any research process. Whether the goal is to understand public opinion, analyse the effectiveness of a medical treatment, or study consumer behaviour, selecting the right sample is central to producing reliable and generalisable results. Probability sampling stands out as one of the most robust approaches available to researchers because it provides every member of the population a known, non-zero chance of being selected.
This blog explores the concept of probability sampling, why it matters, its major types, and practical examples from education, healthcare, social sciences, business research, environmental studies, and technology-based fields.
What is Probability Sampling?
Probability sampling refers to sampling techniques where every unit in the population has an equal or known probability of being included in the sample. Because selection is based on randomness rather than personal judgment, probability samples minimise bias and allow statistical generalisation to the wider population.
Why Probability Sampling Matters
- Ensures representativeness of the target population
- Enables statistical inference, meaning researchers can estimate population parameters
- Reduces sampling bias
- Suitable for large-scale quantitative studies
- Strengthens overall validity and reliability
Probability sampling is widely used in fields such as public health, economics, psychology, marketing, education, environmental monitoring, and political science.
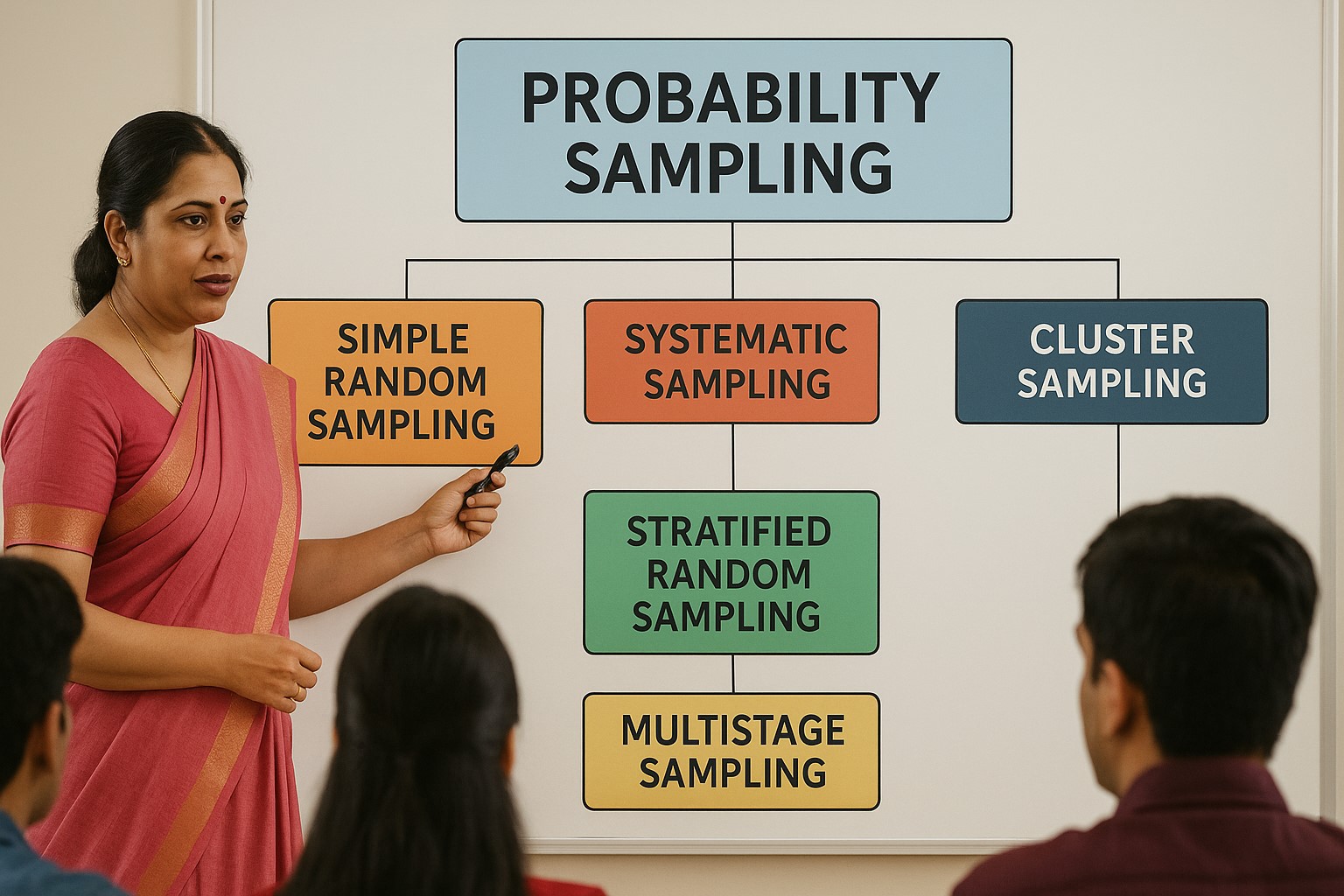
Major Types of Probability Sampling
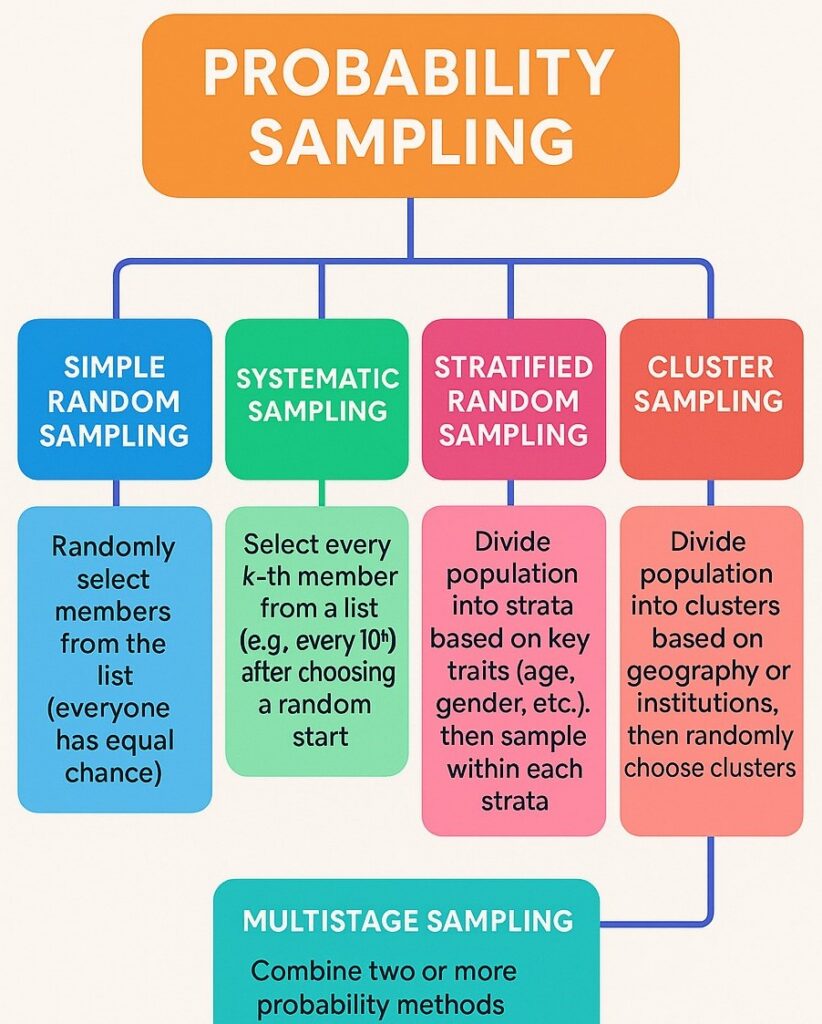
1. Simple Random Sampling (SRS)
This is the most basic form of probability sampling. Every individual has an equal chance of being selected, and the process is entirely random—similar to a lottery draw.
Practical Examples
Education:
A university wants to measure study habits among undergraduate students. From a list of all enrolled undergraduates, 300 students are selected randomly using a computer-generated number system.
Healthcare:
To study dietary patterns, a public health department randomly selects 1,000 households from a city census list.
Business Research:
A company conducting an employee satisfaction survey randomly selects 200 employees across all departments to avoid departmental bias.
2. Systematic Sampling
In this method, researchers select samples using a fixed interval (k). For example, every 5th or 10th member from a list.
Practical Examples
Retail Industry:
A supermarket wants to understand customer shopping patterns. At the billing counter, every 15th customer is surveyed.
Environmental Studies:
To analyse soil quality along a 10 km stretch of farmland, researchers collect soil samples every 200 meters.
Hospital Administration:
To evaluate patient satisfaction, administrators survey every 10th patient discharged from the hospital during the month.
3. Stratified Random Sampling
Here, the population is divided into groups (strata) based on characteristics such as age, gender, income level, education, or region. Then samples are randomly selected from each stratum.
Practical Examples
Social Sciences:
A researcher studying attitudes toward climate change divides the population into strata based on age groups—18–25, 26–40, 41–60, and 60+. Random samples are drawn from each age category to ensure representation.
Human Resources:
A company analysing training needs divides its workforce into strata such as executives, managers, supervisors, and frontline staff. Random samples from each group help understand varying training requirements.
Healthcare:
To evaluate diabetes prevalence, researchers stratify participants by gender and age group. This helps capture variations across demographic groups.
4. Cluster Sampling
The population is split into clusters, usually based on geography or organisation. Instead of sampling from all clusters, only a few are randomly selected, and all individuals within the selected clusters are studied.
Practical Examples
Public Health:
A malaria surveillance study randomly selects certain villages (clusters) in a district. All households in those villages are surveyed.
Education:
To evaluate school performance, researchers randomly select 20 schools in a state and administer assessments to all students in those schools.
Agriculture:
For crop yield estimation, specific agricultural blocks are selected randomly, and data are collected from all farmers within those blocks.
5. Multistage Sampling
This method combines different sampling strategies in multiple steps. It is widely used for large-scale research where sampling the entire population is difficult.
Practical Examples
National Surveys:
Most government surveys (e.g., National Sample Survey, NFHS) use multistage sampling.
Stage 1: Randomly select districts
Stage 2: Randomly select blocks within districts
Stage 3: Randomly select households within blocks
Market Research:
A company evaluating brand penetration first selects cities, then neighbourhoods, and finally households at random.
Education Research:
A study on digital learning outcomes chooses states → districts → schools → individual students.
Types of Probability Sampling
Comparing Probability Sampling across domains
1. Public Health and Medicine
Researchers rely heavily on probability sampling to estimate disease prevalence, testing outcomes, treatment effectiveness, or vaccination rates. For example, during pandemic response studies, stratified sampling helps track differences across age groups or regions.
2. Management and Marketing Research
Companies often use systematic and cluster sampling to understand consumer behaviour, brand loyalty, or service quality. For instance, selecting retail outlets as clusters helps brands evaluate product visibility.
3. Social Sciences and Psychology
Probability sampling ensures fair representation of demographic groups, which is essential for studying social attitudes, behavioural patterns, and cultural variations.
4. Environmental Research
Methods such as systematic and cluster sampling help monitor air quality, biodiversity, or pollution levels across various geographic regions.
5. Technology and IT Research
When studying user satisfaction with online platforms or app usability, simple random sampling ensures unbiased selection of active users.
Advantages of Probability Sampling
- High generalisability
- Transparent and replicable
- Reduces researcher bias
- Allows calculation of sampling errors
- Supports statistical testing and estimation
Challenges
- Time-consuming and sometimes expensive
- Requires complete list of population (sampling frame)
- More complex than non-probability methods in large populations
Despite these limitations, probability sampling remains the gold standard in quantitative research due to its scientific precision and representativeness.
Conclusion
Probability sampling is fundamental to producing high-quality, unbiased, and generalisable research findings. Whether it is assessing public health trends, evaluating customer satisfaction, monitoring soil quality, understanding digital behaviour, or studying social attitudes, probability sampling ensures that researchers capture the diversity of the population in a systematic and statistically reliable manner.
By applying the right probability sampling technique, simple random, systematic, stratified, cluster, or multistage, researchers from all domains can enhance the accuracy and credibility of their findings. It is this rigorous approach to sample selection that ultimately strengthens the validity of evidence-based decision-making across disciplines.






Leave a Reply